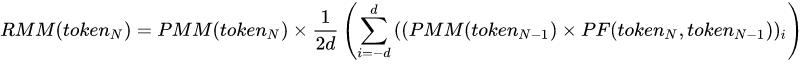|
自然语言处理( NLP ) 是语言学、计算机科学和人工智能的一个子领域,涉及计算机与人类语言之间的交互,特别是如何对计算机进行编程以处理和分析大量自然语言数据。目标是一台能够“理解”文档内容的计算机,包括其中语言的上下文细微差别。然后,该技术可以准确地提取文档中包含的信息和见解,并对文档本身进行分类和组织。
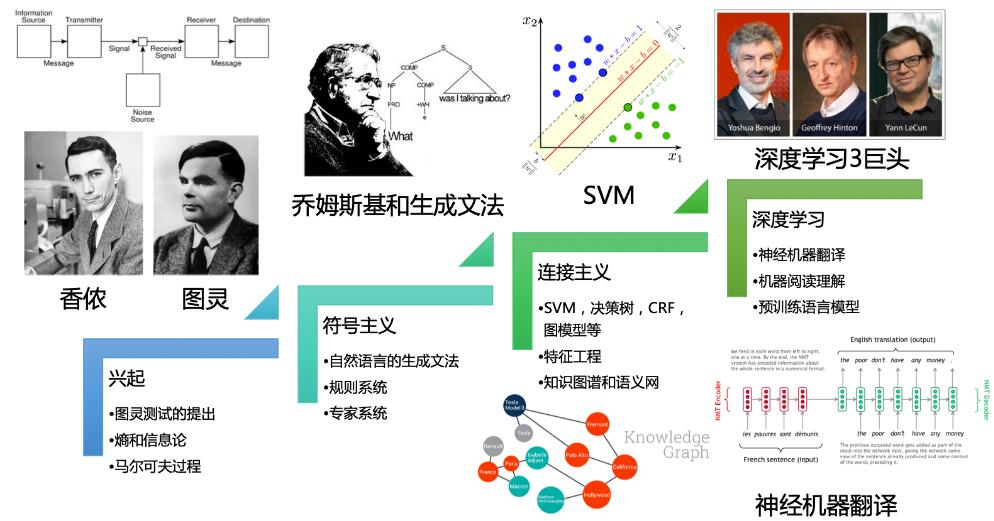
在网页上提供客户服务的自动化在线助手,自然语言处理是主要组件的应用程序示例 自然语言处理中的挑战经常涉及语音识别、自然语言理解和自然语言生成。 历史 自然语言处理起源于1950年代。早在1950年,艾伦·图灵( Alan Turing )就发表了一篇题为“计算机器与智能”的文章,提出了现在所谓的图灵测试作为智能标准,尽管当时并未将其作为与人工智能分开的问题。提议的测试包括一项涉及自然语言自动解释和生成的任务。 符号 NLP(1950年代 -1990年代初期) John Searle的中文房间实验很好地总结了符号 NLP的前提:给定一组规则(例如,中文短语手册,带有问题和匹配的答案),计算机通过以下方式模拟自然语言理解(或其他 NLP 任务)将这些规则应用于它所面临的数据。
1、1950年代:1954年的乔治城实验涉及将60多个俄语句子全自动翻译成英语。作者声称,在三到五年内,机器翻译将成为一个解决问题。 然而,实际进展要慢得多,在1966年ALPAC 报告发现长达十年的研究未能达到预期之后,机器翻译的资金大幅减少。直到1980年代后期,当第一个统计机器翻译系统被开发出来时,才对机器翻译进行了进一步的研究。 2、1960年代:在1960年代开发的一些特别成功的自然语言处理系统是SHRDLU,一种在受限制的“块世界”中工作的自然语言系统,具有有限的词汇,以及ELIZA,一种罗杰里亚心理治疗师的模拟,由Joseph Weizenbaum在1964年至1966年间编写。几乎不使用关于人类思想或情感的信息,ELIZA 有时提供了一种惊人的类人交互。当“患者”超出非常小的知识库时,ELIZA 可能会提供一个通用的响应,例如,用“你为什么说你的头疼?”来响应“我的头疼”。 3、1970年代:在1970年代,许多程序员开始编写“概念本体”,将现实世界的信息结构化为计算机可理解的数据。例如 MARGIE (Schank,1975), SAM (Cullingford,1978), PAM (Wilensky,1978), TaleSpin (Meehan,1976), QUALM (Lehnert,1977), Politics (Carbonell,1979) 和Plot Units (Lehnert1981) )。在此期间,编写了第一个聊天机器人(例如,PARRY)。 4、1980年代:1980年代和1990年代初标志着 NLP 中符号方法的鼎盛时期。当时的重点领域包括基于规则的解析(例如,将HPSG发展为生成语法的计算操作化)、形态学(例如,二级形态学)、语义学(例如,Lesk 算法)、参考(例如,在中心理论中)和自然语言理解的其他领域(例如,在修辞结构理论中)。继续进行其他研究,例如与Racter和Jabberwacky一起开发聊天机器人. 一个重要的发展(最终导致了1990年代的统计转向)是这一时期定量评估的重要性日益提高。
统计 NLP (1990s–2010s) 直到1980年代,大多数自然语言处理系统都基于复杂的手写规则集。然而,从1980年代后期开始,自然语言处理发生了一场革命,引入了用于语言处理的机器学习算法。这是由于计算能力的稳定增长(参见摩尔定律)和乔姆斯基语言学理论(例如转换语法)的主导地位逐渐减弱,其理论基础不鼓励作为机器学习方法基础的语料库语言学。到语言处理。 1、1990年代:NLP 统计方法的许多显着早期成功发生在机器翻译领域,尤其是在 IBM 研究院工作。这些系统能够利用由加拿大议会和欧盟制作的现有多语言文本语料库由于法律要求将所有政府程序翻译成相应政府系统的所有官方语言。然而,大多数其他系统依赖于专门为这些系统实现的任务而开发的语料库,这曾经是(并且经常继续是)这些系统成功的主要限制。因此,大量的研究已经进入了从有限的数据中更有效地学习的方法。 3、2000年代:随着网络的发展,自1990年代中期以来,越来越多的原始(未注释)语言数据变得可用。因此,研究越来越集中在无监督和半监督学习算法上。此类算法可以从尚未使用所需答案手动注释的数据中学习,或者使用注释和非注释数据的组合进行学习。一般来说,这个任务比监督学习要困难得多,并且对于给定数量的输入数据通常会产生不太准确的结果。但是,有大量未注释的数据可用(其中包括万维网的全部内容)),如果使用的算法具有足够低的时间复杂度以实用,则通常可以弥补较差的结果。 神经 NLP(现在) 在2010年代,表示学习和深度神经网络式机器学习方法在自然语言处理中变得普遍。这种流行部分是由于一系列结果表明此类技术 可以在许多自然语言任务中实现最先进的结果,例如在语言建模和解析中。 这在医学和医疗保健中越来越重要,其中 NLP 有助于分析电子健康记录中的笔记和文本,否则在寻求改善护理时将无法进行研究。 方法:规则、统计、神经网络 在早期,许多语言处理系统是通过符号方法设计的,即一组规则的手工编码,再加上字典查找: 例如通过编写语法或设计启发式规则词干。较新的基于机器学习算法的系统比手工生成的规则具有许多优势: 1、机器学习过程中使用的学习过程会自动关注最常见的情况,而在手动编写规则时,通常根本不明显应该将努力指向哪里。 3、自动学习过程可以利用统计推理算法来生成对不熟悉的输入(例如包含以前从未见过的单词或结构)和错误输入(例如拼写错误的单词或意外遗漏的单词)具有鲁棒性的模型。通常,使用手写规则优雅地处理此类输入,或者更一般地说,创建做出软决策的手写规则系统是极其困难、容易出错且耗时的。 3、只需提供更多输入数据,就可以使基于自动学习规则的系统更加准确。然而,基于手写规则的系统只有通过增加规则的复杂性才能变得更加准确,这是一项困难得多的任务。特别是,基于手写规则的系统的复杂性是有限度的,超过这个限度,系统就会变得越来越难以管理。然而,创建更多数据以输入机器学习系统只需要相应增加工时,通常不会显着增加注释过程的复杂性。 尽管机器学习在 NLP 研究中很受欢迎,但符号方法仍然(2020年)常用: 1、当训练数据量不足以成功应用机器学习方法时,例如,对于诸如Apertium系统提供的低资源语言的机器翻译, 2、用于 NLP 管道中的预处理,例如标记化, 3、用于后处理和转换 NLP 管道的输出,例如,从句法分析中提取知识。 统计方法 自1980年代末和1990年代中期所谓的“统计革命” 以来,许多自然语言处理研究都严重依赖机器学习。机器学习范式要求使用统计推断来通过分析典型现实世界示例的大型语料库(语料库的复数形式,是一组文档,可能带有人工或计算机注释) 来自动学习这些规则。 许多不同类别的机器学习算法已应用于自然语言处理任务。这些算法将输入数据生成的大量“特征”作为输入。然而,越来越多的研究集中在统计模型上,该模型基于将实值权重附加到每个输入特征(复值嵌入,和一般的神经网络,例如语音)来做出软概率决策)。此类模型的优势在于,它们可以表达许多不同可能答案的相对确定性,而不仅仅是一个,当此类模型作为更大系统的组件包含时,会产生更可靠的结果。 一些最早使用的机器学习算法,例如决策树,产生了类似于现有手写规则的硬 if-then 规则系统。然而,词性标注将隐藏马尔可夫模型引入自然语言处理,并且越来越多的研究集中在统计模型上,这些模型基于将实值权重附加到构成输入的特征来做出软概率决策数据。许多语音识别所依据的缓存语言模型现在所依赖的系统就是这种统计模型的例子。当给定不熟悉的输入时,此类模型通常更健壮,尤其是包含错误的输入(这在现实世界的数据中很常见),并且在集成到包含多个子任务的更大系统中时会产生更可靠的结果。 自神经转向以来,NLP 研究中的统计方法已在很大程度上被神经网络所取代。然而,它们仍然与需要统计可解释性和透明度的环境相关。 神经网络 统计方法的一个主要缺点是它们需要复杂的特征工程。自2015年以来,该领域因此在很大程度上放弃了统计方法,转而使用神经网络进行机器学习。流行的技术包括使用词嵌入捕获单词的语义属性,并增加对更高级别任务(例如,问答)的端到端学习,而不是依赖于单独的中间任务(例如,词性标记和依赖)的管道解析)。在某些领域,这种转变导致 NLP 系统的设计方式发生了重大变化,因此基于深度神经网络的方法可能被视为不同于统计自然语言处理的新范式。例如,术语神经机器翻译(NMT) 强调了这样一个事实,即基于深度学习的机器翻译方法直接学习序列到序列的转换,从而消除了对单词对齐和语言建模等中间步骤的需求。统计机器翻译(SMT)。 常见的 NLP 任务 以下是自然语言处理中一些最常研究的任务列表。其中一些任务具有直接的实际应用程序,而其他任务更通常用作用于帮助解决更大任务的子任务。尽管自然语言处理任务密切相关,但为了方便起见,它们可以细分为类别。下面给出粗略的划分。 文本和语音处理 光学字符识别(OCR) 给定一个代表打印文本的图像,确定相应的文本。 语音识别 给定一个或多个人说话的声音片段,确定语音的文本表示。这与文本到语音的相反,是通俗称为“ AI-complete ”的极其困难的问题之一(见上文)。在自然语音中,连续单词之间几乎没有任何停顿,因此语音分割是语音识别的必要子任务(见下文)。在大多数口语中,表示连续字母的声音在称为协同发音的过程中相互混合,因此模拟信号的转换离散字符可能是一个非常困难的过程。此外,鉴于口音不同的人使用相同语言的单词,语音识别软件必须能够将各种输入识别为在文本等价方面彼此相同。 语音分割 给定一个或多个人说话的声音片段,将其分成单词。语音识别的子任务,通常与其分组。 文字转语音 给定一个文本,转换这些单元并产生一个语音表示。文字转语音可用于帮助视障人士。 分词(分词) 将一大段连续文本分成单独的单词。对于像English这样的语言,这是相当简单的,因为单词通常用空格分隔。然而,一些书面语言,如中文、日文和泰文,并没有以这种方式标记单词边界,在这些语言中,文本分割是一项重要的任务,需要了解该语言中单词的词汇和形态。有时,此过程也用于数据挖掘中的词袋(BOW) 创建等情况。 形态分析 词形还原 仅删除屈折词尾并返回单词的基本字典形式的任务,也称为引理。词形还原是另一种将单词简化为规范化形式的技术。但在这种情况下,转换实际上使用字典将单词映射到它们的实际形式。 形态分割 将单词分成单独的语素并识别语素的类别。这项任务的难度很大程度上取决于所考虑语言的形态(即词的结构)的复杂性。英语有相当简单的形态,尤其是屈折形态,因此通常可以完全忽略这个任务,而简单地将一个单词的所有可能形式(例如,“open, opens, opens, opening”)建模为单独的单词。在土耳其语或Meitei等语言中,[22]然而,在印度语言中,这种方法是不可能的,因为每个字典条目都有数千种可能的词形。 词性标注 给定一个句子,确定每个单词的词性(POS)。许多词,尤其是常用词,可以作为多个词类。例如,“book”可以是名词(“the book on the table”)或动词(“to book a flight”);“set”可以是名词、动词或形容词;而“out”可以是至少五个不同词类中的任何一个。 词干 将变形(或有时派生)的词简化为基本形式的过程(例如,“close”将是“close”、“close”、“close”、“closer”等的词根)。词干提取与词形还原产生相似的结果,但这样做是基于规则,而不是字典。 句法分析 语法归纳 生成描述语言语法的正式语法。 断句(也称为“句界消歧”) 给定一段文本,找到句子的边界。句子边界通常由句点或其他标点符号标记,但这些相同的字符可以用于其他目的(例如,标记缩写)。 解析 确定给定句子的解析树(语法分析)。自然语言的语法是模棱两可的,典型的句子有多种可能的分析:也许令人惊讶的是,一个典型的句子可能有数千个潜在的解析(其中大部分对人类来说似乎完全没有意义)。解析有两种主要类型:依赖解析和选区解析。依赖解析侧重于句子中单词之间的关系(标记诸如主要对象和谓词之类的东西),而选区解析侧重于使用概率上下文无关文法(PCFG) 构建解析树(另请参见随机语法)。 词汇语义(上下文中的单个单词) 词汇语义 上下文中单个单词的计算意义是什么? 分布语义 我们如何从数据中学习语义表示? 命名实体识别(NER) 给定一个文本流,确定文本中的哪些项目映射到专有名称,例如人或地点,以及每个此类名称的类型(例如人、位置、组织)。尽管大写可以帮助识别诸如英语之类的语言中的命名实体,但此信息不能帮助确定命名实体的类型,并且在任何情况下,通常都是不准确或不充分的。 例如,一个句子的第一个字母也是大写的,命名实体通常跨越几个单词,其中只有一些是大写的。此外,非西方文字中的许多其他语言(例如中文或阿拉伯语)) 根本没有任何大写字母,甚至带有大写字母的语言也可能不会始终使用它来区分名称。例如,德语将所有名词大写,无论它们是否是名称,而法语和西班牙语不将用作形容词的名称大写。 情绪分析(另见多模态情绪分析) 通常从一组文档中提取主观信息,通常使用在线评论来确定特定对象的“极性”。它对于识别社交媒体中的舆论趋势以及营销特别有用。 术语提取 术语提取的目标是从给定的语料库中自动提取相关术语。 词义消歧(WSD) 许多词有不止一种含义;我们必须选择在上下文中最有意义的含义。对于这个问题,我们通常会得到一个单词列表和相关的词义,例如来自字典或WordNet等在线资源。 实体链接 许多词——通常是专有名称——指的是命名实体;在这里,我们必须选择上下文中引用的实体(名人、地点、公司等)。 关系语义(单个句子的语义) 关系抽取 给定一段文本,确定命名实体之间的关系(例如,谁与谁结婚)。 语义解析 给定一段文本(通常是一个句子),生成其语义的形式表示,或者作为图形(例如,在AMR 解析中)或按照逻辑形式(例如,在DRT 解析中)。这一挑战通常包括来自语义的几个更基本的 NLP 任务的各个方面(例如,语义角色标记、词义消歧),并且可以扩展到包括完整的话语分析(例如,话语分析、共指;参见下面的自然语言理解) . 语义角色标签(另请参见下面的隐式语义角色标签) 给定一个句子,识别和消除语义谓词(例如,口头框架),然后识别和分类框架元素(语义角色)。 话语(超越单个句子的语义) 共指解析 给定一个句子或更大的文本块,确定哪些词(“提及”)指的是相同的对象(“实体”)。照应解析是该任务的一个具体示例,特别关注将代词与其所指的名词或名称进行匹配。共指解析的更一般任务还包括识别涉及引用表达式的所谓“桥接关系” 。例如,在“他从前门进入约翰的房子”这样的句子中,“前门”是一个指称表达,要识别的桥接关系是被指的门是约翰的前门。' 话语分析 这个量规包括几个相关的任务。一项任务是语篇解析,即识别连接文本的语篇结构,即句子之间的语篇关系的性质(例如阐述、解释、对比)。另一个可能的任务是识别和分类文本块中的语音行为(例如,是-否问题、内容问题、陈述、断言等)。 隐式语义角色标签 给定一个句子,识别和消除语义谓词(例如,语言框架)及其在当前句子中的显式语义角色(参见上面的语义角色标签)。然后,识别当前句子中未明确实现的语义角色,将它们分类为文本中其他地方明确实现的参数和未指定的参数,并根据本地文本解决前者。一个密切相关的任务是零照应解析,即将共指解析扩展到支持删除语言。 识别文本蕴涵 给定两个文本片段,确定一个为真是否包含另一个,是否包含另一个的否定,或允许另一个为真或假。 主题分割和识别 给定一段文本,将其分成多个段,每个段专门用于一个主题,并确定该段的主题。 参数挖掘 论证挖掘的目标是借助计算机程序从自然语言文本中自动提取和识别论证结构。这样的论证结构包括前提、结论、论证方案以及主要和次要论证之间的关系,或话语中的主要和反论点。 高级 NLP 应用程序 自动摘要(文本摘要) 生成一段文本的可读摘要。通常用于提供已知类型文本的摘要,例如研究论文、报纸金融版的文章。 图书生成 不是自然语言处理任务本身,而是自然语言生成和其他 NLP 任务的扩展,是创建成熟的书籍。第一本机器生成的书是在1984年由基于规则的系统创建的(Racter, The policeman's beard is half-constructed)。神经网络发表的第一部作品于2018年出版,以小说形式销售的《路1》包含 6000万字。这两个系统基本上都是复杂但无意义(无语义)的语言模型。第一本机器生成的科学书籍于2019年出版(Beta Writer, Lithium-Ion Batteries , Springer, Cham)。不像Racter和1 the Road,这是基于事实知识和基于文本摘要的。 对话管理 旨在与人类交谈的计算机系统。 文档 AI Document AI 平台位于 NLP 技术之上,使以前没有人工智能、机器学习或 NLP 经验的用户能够快速训练计算机从不同的文档类型中提取他们需要的特定数据。NLP 支持的 Document AI 使非技术团队能够快速访问隐藏在文档中的信息,例如律师、业务分析师和会计师。 语法错误纠正 语法错误检测和纠正涉及语言分析各个层面(音韵/正字法、词法、句法、语义、语用学)的大量问题。语法错误纠正是有影响的,因为它影响到数以亿计使用或学习英语作为第二语言的人。因此,自2011年以来,它一直受到许多共享任务的影响。 就正字法、词法、句法和语义的某些方面而言,并且由于强大的神经语言模型的发展,例如作为GPT-2,现在(2019年)可以认为这是一个已基本解决的问题,并且正在各种商业应用中销售。 机器翻译 自动将文本从一种人类语言翻译成另一种。这是最困难的问题之一,并且是通俗称为“ AI-complete ”的一类问题的成员,即需要人类拥有的所有不同类型的知识(语法、语义、关于现实世界的事实等) .) 正确解决。 自然语言生成(NLG): 将计算机数据库或语义意图中的信息转换为可读的人类语言。 自然语言理解(NLU) 将文本块转换为更正式的表示形式,例如更易于计算机程序操作的一阶逻辑结构。自然语言理解涉及从多种可能的语义中识别预期的语义,这些语义可以从自然语言表达中派生出来,自然语言表达通常采用自然语言概念的有组织的符号形式。 语言元模型和本体的引入和创建是有效的但经验性的解决方案。自然语言语义的显式形式化,不会与隐含假设混淆,例如封闭世界假设(CWA) 与开放世界假设,或主观是/否与客观真/假的构建语义形式化的基础。 问答 给定一个人类语言问题,确定它的答案。典型的问题有特定的正确答案(例如“加拿大的首都是什么?”),但有时也会考虑开放式问题(例如“生命的意义是什么?”)。 文本到图像生成 给定图像的描述,生成与描述匹配的图像。 文本到场景生成 给定场景的描述,生成场景的3D 模型。 一般趋势和(可能的)未来方向 基于该领域的长期趋势,可以推断 NLP的未来方向。截至2020年,可以观察到长期存在的 CoNLL 共享任务系列主题中的三个趋势: 1、对自然语言越来越抽象的“认知”方面的兴趣(1999-2001:浅解析,2002-03:命名实体识别,2006-09/2017-18:依赖语法,2004-05/2008-09语义角色标签,2011-12共指,2015-16:话语解析,2019:语义解析)。 2、对多语言和潜在多模态的兴趣日益增加(自1999年以来为英语;自2002年以来西班牙语、荷兰语;自2003年以来德语;自2006年以来保加利亚语、丹麦语、日语、葡萄牙语、斯洛文尼亚语、瑞典语、土耳其语;巴斯克语、加泰罗尼亚语、汉语、希腊语、匈牙利语、意大利语、土耳其语,从2007年开始;捷克语从2009年开始;阿拉伯语从2012年开始;2017年:40多种语言;2018年:60+/100多种语言) 3、消除符号表示(基于规则的对弱监督方法、表示学习和端到端系统的过度监督) 认知与 NLP 大多数高级 NLP 应用程序涉及模拟智能行为和对自然语言的明显理解的方面。更广泛地说,认知行为的日益先进方面的技术操作化代表了 NLP的发展轨迹之一(参见上文 CoNLL 共享任务之间的趋势)。 认知是指“通过思想、经验和感官获得知识和理解的心理活动或过程”。 认知科学是对心智及其过程的跨学科科学研究。认知语言学是语言学的一个跨学科分支,结合了心理学和语言学的知识和研究。特别是在符号 NLP时代,计算语言学领域与认知研究保持着密切的联系。 例如,George Lakoff提供了一种从认知科学的角度构建自然语言处理 (NLP) 算法的方法,以及认知语言学的发现,具有两个定义方面: 1、应用概念隐喻理论,Lakoff 将其解释为“根据另一个想法理解一个想法”,它提供了作者意图的想法。例如,考虑英文单词“big”。当用于比较时(“那是一棵大树”),作者的意图是暗示这棵树相对于其他树或作者的经验来说是“物理上的大” 。当用作隐喻时(“明天是大日子”),作者的意图是暗示“重要性”。其他用法背后的意图,例如“她是个大人物”在没有额外信息的情况下,对于人和认知 NLP 算法来说,仍然会有些模棱两可。 2、根据被分析的文本片段之前和之后呈现的信息,例如通过概率上下文无关语法(PCFG),为单词、短语、句子或文本片段分配意义的相对度量。美国专利9269353中介绍了此类算法的数学方程:
如何看? RMM , 是意义的相对量度 token , 是文本、句子、短语或单词的任何块 N , 是被分析的令牌数量 PMM , 是基于语料库的意义的可能度量 d ,是令牌在N-1个令牌序列中的位置 PF,是特定于语言的概率函数 与认知语言学的联系是 NLP 历史遗产的一部分,但自1990年代统计转向以来,它们很少得到解决。然而,在各种框架的背景下,已经在开发针对技术上可操作框架的认知模型的方法,例如,认知语法、功能语法、构造语法、计算心理语言学和认知神经科学(例如,ACT-R),然而,在主流 NLP 中的使用有限(通过参加 ACL的主要会议 来衡量)。最近,认知 NLP的想法作为一种实现可解释性,例如,在“认知人工智能”的概念下。同样,认知 NLP的想法是神经模型多模态NLP 所固有的(尽管很少明确表示)。 |